When Cost Optimization Meets Reality: Making Database Restores Effortless with Temporary Storage Expansion
At Lucidity, we’ve always believed infrastructure should take care of itself.
Our mission as a NoOps platform is simple: eliminate the constant operational overhead of managing storage. DevOps teams shouldn’t have to wake up at midnight worrying about disk space, scramble over weekends to expand volumes, or over-provision capacity “just in case.”
Lucidity automatically scales storage up and down based on real usage. Applications get the capacity they need, when they need it. Costs stay optimized. Engineers sleep peacefully.
Most of the time, this works seamlessly.
But real-world operations aren’t always predictable.
The Moment When Automation Meets Exception
One of the most critical operations in any production environment is a database restore.
Whether it’s disaster recovery, cloning environments, or restoring backups for compliance or debugging, restore operations behave very differently from normal workload patterns.
Unlike typical application growth - which is gradual and predictable - database restores often require sudden, massive disk allocation.
A restore might need:
- 2x the current disk capacity
- Sometimes 3X or more
- All at once, immediately
This is fundamentally different from organic growth.
And because restores are infrequent, temporary events, permanently increasing disk capacity just to accommodate them defeats the purpose of cost optimization.
Without the right mechanism, teams are forced into uncomfortable tradeoffs:
- Manually expanding disks
- Over-provisioning storage permanently
- Accepting operational risk and complexity
This is exactly the kind of operational friction NoOps is meant to eliminate.
The Real Requirement: Temporary Headroom, On Demand
When we looked closely at how teams handle restores, the requirement was surprisingly straightforward:
“Give me extra capacity exactly when I need it - and remove it automatically when I’m done.”
Not permanent expansion.
Not manual intervention.
Not over-provisioning.
Just temporary, controlled headroom.
And most importantly - something that fits directly into existing workflows.
Introducing Lucidity’s Temporary Disk Expansion APIs
To solve this, Lucidity introduced a simple, API-driven way to temporarily expand disk capacity for exceptional workflows like database restores.
With a single API call, users can:
- Instantly expand disk capacity for an instance
- Run their restore operation safely
- Automatically revert to optimized capacity when done
No manual resizing. No permanent cost impact.
No operational stress.
How It Works: Buffer → Restore → Revert

The workflow is intentionally simple and integrates cleanly into any automation or restore process.
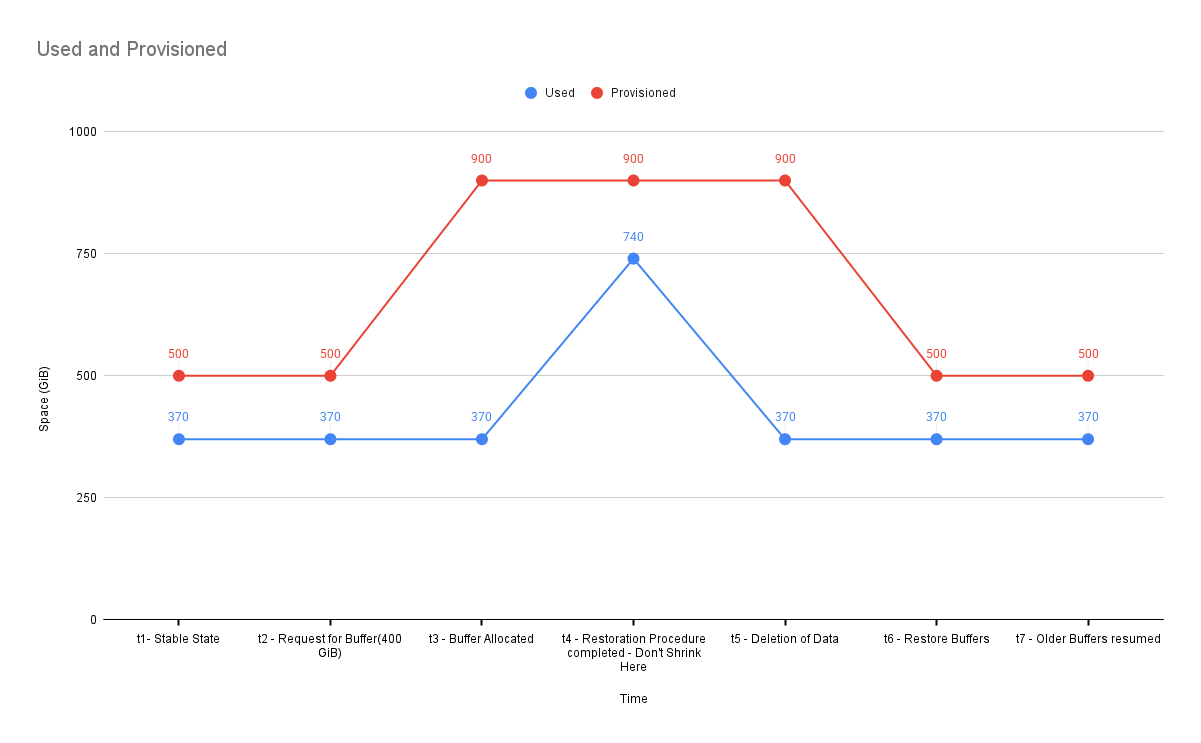
Step 1: Add Temporary Capacity Buffer
Before starting the restore, users call Lucidity’s API to request additional temporary capacity.
This can be done via:
- REST API
- CLI
- PowerShell
- Integrated scripts or restore workflows
Lucidity immediately provisions the requested headroom.
The restore can now proceed without risk of capacity failures.
Step 2: Run the Database Restore
Once the buffer is in place, the restore runs exactly as expected.
No changes to database tools.
No special handling required.
To the database, the disk simply has enough space.
Step 3: Revert Automatically to Optimized Capacity
After the restore completes, another API call removes the temporary buffer.
Lucidity automatically:
- Removes the temporary expansion
- Restores normal autoscaling behavior
- Returns the system to its cost-optimized baseline
No leftover over-provisioning. No wasted storage.
Built for Automation and Real-World Workflows
These APIs are designed to fit naturally into existing operational pipelines.
They can be embedded directly into:
- SQL Server Agent Jobs
- Backup and restore automation
- CI/CD pipelines
- Disaster recovery workflows
- Third-party tools like Commvault, Veeam, or Rubrik
From the operator’s perspective, it becomes seamless:
Restore starts → Capacity expands automatically → Restore completes → Capacity returns to normal.
Zero manual intervention.
Preserving Both Reliability and Cost Optimization
This capability reinforces the core promise of Lucidity:
Reliability and cost efficiency should never be in conflict.
Teams should never have to choose between:
- Ensuring successful restores
or - Maintaining optimized infrastructure costs
With temporary disk expansion APIs, they get both.
Storage adapts instantly during exceptional events — and returns to efficiency immediately afterward.
NoOps Means Handling Both the Common Path and the Exceptional Path
True NoOps isn’t just about handling predictable growth.
It’s about gracefully handling the unpredictable moments too — restores, migrations, spikes, and recovery scenarios — without introducing manual effort, risk, or permanent cost overhead.
Lucidity ensures your infrastructure remains:
- Autonomous
- Efficient
- Reliable
- And operationally effortless
Even during the most critical moments.
Table of Contents
Sign Up
Shantanu Challa