Cassandra storage costs hide in plain sight. A healthy production cluster runs at 30–60% disk utilization by design, which means roughly half the storage on your bill is headroom you're paying for and never use.
If you've ever operated Cassandra in production, you've made peace with a strange fact: a healthy cluster is a half-empty cluster.
The DataStax capacity guidance is to keep nodes between 50% and 80% utilized. The Cassandra operator handbook draws a similar line in the sand. Run hotter than that, and the database starts working against you. Compactions slow, write latency drifts, and on a bad day you wake up to a node that has flipped itself read-only because it ran out of room to merge a single SSTable.
So the standard answer is: provision for the worst case. Buy the disk you'll need at peak, plus headroom for compaction, plus a margin for the on-call engineer's nervous system. And then pay for all of it, every hour, forever.

This post is about why Cassandra storage is genuinely hard to right-size, what that hardness actually costs you across four different dimensions, and what a different shape of solution looks like. We'll close with a real production wrinkle we hit while building one at Lucidity.
Why Cassandra storage is hard to right-size
Cassandra is an LSM-tree database. Writes go to the commit log and a memtable, and once a memtable fills up, it gets flushed to disk as an immutable SSTable. SSTables don't get edited, they get merged. That merge process is compaction, and it's the single most important thing to understand about Cassandra storage.
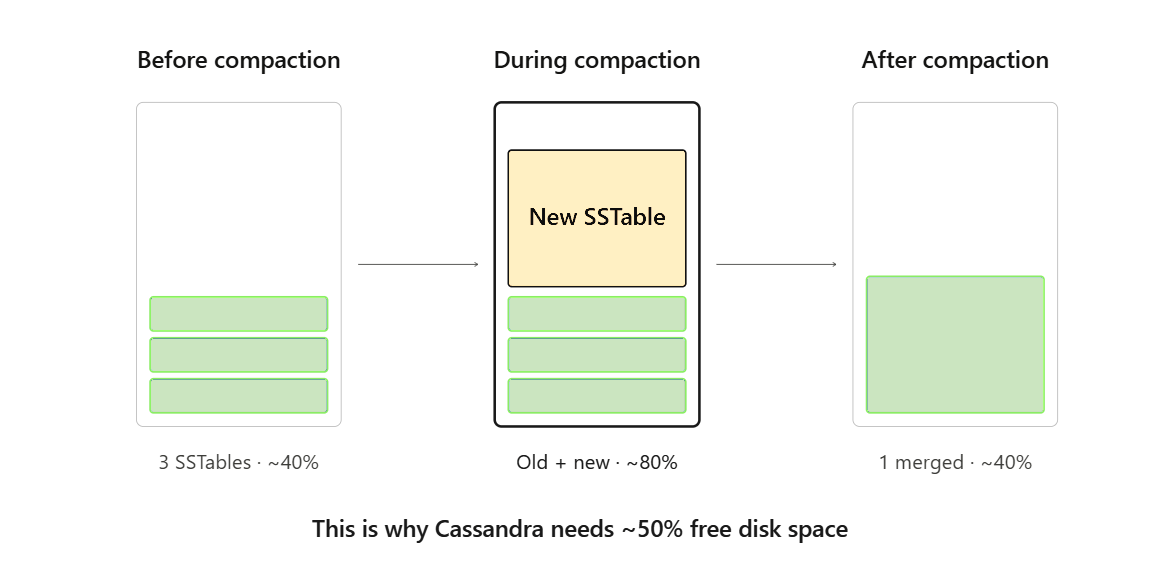
Compaction needs free space to do its job. With Size-Tiered Compaction Strategy (STCS, the default), the worst case is roughly half the disk: a major compaction can temporarily produce an output SSTable as large as the sum of its inputs, and you need both on disk simultaneously. Leveled Compaction (LCS) is gentler on space (fixed-size SSTables and bounded levels keep the multiplier small) but trades that for write amplification. Time-Window Compaction (TWCS) is great for time-series and TTL'd data but assumes a workload shape that not everyone has.
Add to this the things that don't show up in your data model:
- Tombstones that linger until gc_grace_seconds has passed and a compaction sweeps them.
- Snapshots taken before truncates, repairs, or schema changes — easy to forget, easy to leave on disk.
- Repair streams that can briefly double a node's footprint while data flows in.
- Bootstrapping new nodes pulling data across the network onto fresh disks.
The net effect: Cassandra's real storage requirement is more than your data size. It's your data size plus a hard-to-predict tail that depends on compaction strategy, repair cadence, deletion patterns, and timing luck.
The hidden costs of Cassandra over-provisioning
Cluster operators usually frame this as one problem (i.e. "we need more disk") but it's really four problems that the same static over-provisioning hides at the same time:
1. Cost waste, paid silently. A 50% utilization target on a multi-terabyte fleet means you are renting roughly twice the storage you actually use. Across hundreds of nodes, that's a significant, recurring line item that doesn't show up as anomalous in any FinOps tool because it's normal. The waste is by design. That's what makes it hard to attack.
2. Operational toil. Even with healthy headroom, growth eventually catches up. Now someone is running a runbook to expand EBS or Azure Managed Disk, waiting for the volume to finish transitioning, growing the partition, growing the filesystem, and praying the node doesn't fall behind on writes during the procedure. Multiply by the number of times this happens per quarter, multiply by the number of clusters. This frequent, interrupting style of work takes a toll, almost always done late, almost always under pressure.
3. Incidents. When over-provisioning isn't enough, or growth was steeper than the forecast, Cassandra's behavior on a full disk is unforgiving. The default disk_failure_policy = stop will take the node out of gossip. best_effort will keep it alive but blacklist drives. Either way, you've lost a replica at the worst possible moment. Compaction failures during the spiral compound the problem: you can't free space without space.
4. The elasticity gap. The cloud was supposed to make this easy. Block storage in AWS, Azure, and GCP all support live expansions. The trouble is that "the disk got bigger" is only step one. There are multiple elements that must grow as well, from the filesystem to the mount, all while the application must stay undisturbed. This is easier said than done on sensitive, write-heavy databases, for example.
A note from the field
At Lucidity, we've been running storage autoscaling for Cassandra workloads in production, and our experience is that the elasticity gap is real and lives at the boundary between the block layer and the filesystem.
Recently, on a high-write Cassandra node, resize coincided with a particularly intense compaction window. The block device expanded cleanly. The filesystem accepted the new space. But for a short period during the resize, write throughput on the node stalled. The filesystem held briefly, Cassandra's write path felt the back-pressure, and the node's pending mutations queue ticked up before recovery.
Nothing was lost. Replication did its job. But the lesson was clear: a storage layer that "supports" Cassandra has to do more than expand on demand. It has to understand that this database treats the I/O queue as part of its correctness model, and that any moment of filesystem hesitation is a moment of write-path hesitation. That’s why we should treat Cassandra's quirks as first-class, not as a generic block-storage customer.
This is the part of "live elasticity" that doesn't fit on a slide: the database tells you what it needs, and the storage layer either listens or causes incidents.
What Cassandra-aware storage autoscaling requires
Pulling the threads together, the requirements list is short and unforgiving:
- Continuously observe utilization at the filesystem level, not just the block device. Cassandra fills up data_file_directories long before the volume hits its API-reported limit.
- Resize the block device and the filesystem online, with no unmount, no remount, no Cassandra restart. A node that has to bounce to grow its disk is a node that has to bootstrap its way back into the ring.
- Be aware of the compaction state. Don't expand mid-compaction-storm if you can sequence around it. Don't shrink if a snapshot or repair is in flight.
- Respect the commit log. It has its own access pattern, its own latency budget, and often its own disk. Treat it separately.
- Know the failure policy. A storage layer that drifts a node into Cassandra's stop policy has not solved a problem; it has caused one.
- Reclaim space, not just add it. Tombstone-heavy and TTL-heavy workloads release real capacity back to the filesystem. Live elasticity should give that capacity back to the cloud bill.
A storage layer that does these things turns the four problems above from architectural facts into operational non-events. Cost waste shrinks because nodes can run hotter without running scared. Toil disappears because resizes happen automatically. Incidents from full disks become rare because growth is continuous, not stepwise. And the elasticity gap closes — the cloud's "live resize" finally behaves like the database needs it to.
Where Lucidity fits
Lucidity AutoScaler is built for this shape of problem. It runs alongside your Cassandra nodes, watches utilization continuously, and grows or shrinks the underlying block storage and filesystem based on real-time data demands without restarts or downtime, without manual runbooks, and without leaving headroom on the table that you're paying for and not using.

We're not going to claim it's been perfectly smooth from day one. The incident above is exactly the kind of edge that only a database like Cassandra surfaces, and the only way to learn it is to operate it. What we will claim is that we've done the work to meet Cassandra where it actually lives — in the queue depths, the compaction windows, the commit log latency, the disk failure policy — and that the cluster you run on top of it should feel less like an exercise in over-provisioning and more like a system that fits its own footprint.
If your Cassandra fleet is sized for the worst case and billed for it every month, there is a different way to do this. Talk to us, or run a free, self-serve Assessment to measure the half that's empty, and ask what it's costing you.
Frequently Asked Questions
Why does Cassandra use so much disk space?
Cassandra is an LSM-tree database that writes data as immutable SSTables and merges them through compaction. Compaction requires free disk space to hold both the input and output SSTables simultaneously. With Size-Tiered Compaction Strategy (STCS), the worst case requires roughly 50% free disk. Additional space is consumed by tombstones awaiting gc_grace_seconds expiry, snapshots from truncates and repairs, repair streams, and new node bootstrapping. As a result, production clusters typically run at 50-60% disk utilization even when healthy.
What is the recommended disk utilization for Cassandra nodes?
DataStax capacity guidance recommends keeping Cassandra nodes between 50% and 80% disk utilization. The Cassandra operator handbook draws a similar threshold. Running above 80% risks compaction failures, increased write latency, and nodes flipping to read-only mode when they run out of room to merge SSTables. This means 20-50% of provisioned storage is reserved headroom that appears on your cloud bill but is never used for data.
How does compaction affect Cassandra storage requirements?
Compaction merges multiple SSTables into fewer, larger ones to reclaim space from deleted or overwritten data. During a compaction, the database temporarily needs enough free disk to hold both the old SSTables and the new output SSTable at the same time. With Size-Tiered Compaction (STCS), a major compaction can temporarily require up to 50% of disk capacity in free space. Leveled Compaction (LCS) uses less temporary space but increases write amplification. Time-Window Compaction (TWCS) works well for time-series data but assumes a specific workload pattern.
What happens when a Cassandra node runs out of disk space?
When a Cassandra node fills its disk, behavior depends on the configured disk_failure_policy. The default setting (stop) removes the node from gossip entirely, taking a replica offline at the worst possible moment. The best_effort setting keeps the node alive but blacklists affected drives. In both cases, compaction failures compound the problem because Cassandra cannot free space without having space to run compaction. This can create a cascading failure loop that requires manual intervention to resolve.
How much does Cassandra over-provisioning cost?
Cassandra over-provisioning creates four categories of hidden cost. First, a 50% utilization target across a multi-terabyte fleet means roughly half the storage bill pays for unused headroom, a recurring expense that doesn't show up as anomalous in FinOps tools because it's by design. Second, growth eventually forces manual volume expansions (EBS or Azure Managed Disk resizes, partition and filesystem grows) that create operational toil. Third, when headroom runs out unexpectedly, full-disk incidents can take nodes offline and trigger cascading compaction failures. Fourth, an elasticity gap exists because cloud "live resize" requires multiple coordinated steps beyond the block device expansion that can disrupt write-heavy workloads.
Can you autoscale Cassandra storage in the cloud?
Yes, but effective Cassandra storage autoscaling requires more than basic volume resizing. A Cassandra-aware autoscaler must monitor utilization at the filesystem level (not just the block device), resize the block device and filesystem online with no unmount or restart, account for compaction state and avoid expanding mid-compaction-storm, respect the commit log's separate latency requirements, understand Cassandra's disk failure policy, and reclaim unused space from tombstone-heavy or TTL-heavy workloads. Lucidity AutoScaler is built for this purpose, running alongside Cassandra nodes to grow or shrink storage based on real-time demand without downtime or manual runbooks.
What is the elasticity gap in cloud storage for databases?
The elasticity gap refers to the difference between what cloud providers advertise ("live volume expansion") and what databases like Cassandra actually need. Expanding a block device is only the first step. The filesystem must also grow, the mount must be updated, and all of this must happen while the database continues serving reads and writes without disruption. On write-heavy Cassandra nodes, even brief filesystem hesitation during a resize can cause write-path back-pressure and pending mutation queue spikes. Closing the elasticity gap requires a storage layer that understands the database's I/O patterns and sequences resizes around sensitive operations like compaction.
How can I reduce Cassandra storage costs without risking downtime?
The safest approach to reducing Cassandra storage costs is continuous, automated right-sizing rather than static over-provisioning. A storage autoscaler that monitors disk utilization in real time and grows or shrinks volumes based on actual demand lets nodes run at higher utilization without the risk of disk-full incidents. This eliminates the need for large static headroom buffers, removes manual resize toil, and returns unused capacity from tombstone and TTL cleanups back to the cloud bill. Lucidity offers a free, self-serve Assessment that measures current utilization across your Cassandra fleet and quantifies the savings opportunity.
Table of Contents
Sign Up
Satyesh Anand